Beware of "Read-Only Bank Access"
After moving to the United States, I have come across this reassuring statement fairly often:
<Product name> only has read access to your accounts. Nobody can authorize any transactions on your behalf, not even <product name>.
This is a particularly popular thing for services like Mint and Credit Karma to say in an effort to get you to give up the holiest of holies: The login credentials to your online banking accounts. This “guarantee” is also completely false, or at least incredibly deceptive.
There’s no such thing as “read-only access” to your Chase banking or American Express card accounts. Services like Mint and Credit Karma store your real usernames and passwords on their servers, not some kind of read-only token. If their servers get compromised, your linked bank accounts may very well be fully compromised as well.
Here’s the kicker: These services know this full-well. When you sign up for any of them, you’re agreeing that they bear no responsibility in the case of a compromise. (Read the fine print.) Your money is now gone, and they won’t be there to help you. FDIC won’t help you either—that only protects you if your financial institution becomes insolvent, not if your accounts are compromised.
What these companies actually seem to mean when they say that their access is “read-only” is that there is no functionality within their interfaces which allows people to authorize transactions and perform other changes, not that the credentials they’re storing can’t be used to do absolutely anything on your accounts. (The former borders on the irrelevant, of course, and the latter is what most people actually care about.)
Carefully evaluate whether you want to trust these companies based on these “protections” and the way they present them, and remember they won’t be there for you if things go wrong.
(To give a little perspective: Intuit, the company that develops Mint, Quicken, and QuickBooks, lets you encrypt your Quicken data file using a password, but only allows that password to consist of 15 characters or less. This is their supposedly “military-grade security system;” 15 characters isn’t even enough to reach 128-bit security, the lowest acceptable level for strong security.)
If you’re currently using any of these services, and want to reduce your risk, deleting your linked accounts within the service and/or the service account itself, as well as changing the password for each of your linked accounts should do the trick.
Gambling with Secrets: an Introduction to Cryptography
Art of the Problem is a team of people making web video series about great problems. Their first series is an introduction to cryptography and cryptanalysis, and it’s one of the most approachable I’ve seen.
If you’ve ever asked yourself questions like:
- How can two people communicate securely even if somebody is listening in on the conversation?
- How can two people have an encrypted conversation without meeting?
- What does randomness mean? Are things that “look random” secure?
- What is the most secure cryptographic cipher?
- How did the Allied Forces break Nazi Germany’s “super-secure” Enigma machine during World War II?
…you’ll enjoy this miniseries.
No special background in mathematics is required, and it touches on many subtle mistakes that huge companies are still making today. It consists of 8 parts/chapters, each lasting about 5-10 minutes.
Part 1: Introduction to Cryptography
Part 2: Prime Factorization
Part 3: Probability Theory & Randomness
Part 4: Private Key Cryptography
Part 5: Encryption Machines
Part 6: Perfect Secrecy & Pseudorandomness
Part 7: Diffie-Hellman Key Exchange
Part 8: RSA Encryption
For more, visit their website.
The Secure Remote Password Protocol Isn't Bad
Blizzard Entertainment has been receiving a lot of flak recently for using the Secure Remote Password protocol for password authentication in their Battle.net service because SRP doesn’t provide the same level of protection against offline attacks that one-way key derivation and password hash functions like PBKDF2, bcrypt, and scrypt do.
I applaud them. Well done, Blizzard. You’ve done more to protect your users than most other companies that handle user passwords. It is great to see a company employ real safeguards like SRP and two-factor authentication (which you introduced long before it was cool.)
All of the recent criticism of Blizzard’s design decisions kind of misses the point. SRP was designed to prevent eavesdropping attacks (by never transmitting the password over the wire,) not dictionary attacks against the password verifiers (the kind of digests that are stored on the server side.) This is akin to blaming Diffie-Hellman key exchange for the fact that DES is easy to break, since the SRP authors never made any claim that the verifiers were resistant to dictionary attacks.
Blizzard absolutely made the right choice by choosing not to transmit passwords over the wire. The people who are suggesting that they throw out SRP on the client side for a KDF on the server side seem to completely miss that this would only switch out one security vulnerability with another. A better solution would be to employ a one-way key derivation function on the client side, store the salt on the server side (so any client can produce the same digest for the same account, even if it’s on another machine,) and then transmit the verification “digest” (or proof of it) in a non-revealing/non-reusable way (if the traffic is snooped, or the verifiers are compromised,) the latter being precisely what SRP does.
The above would provide more protection against password compromise than the password authentication used by virtually all web applications and almost all desktop clients. It seems strange to me to criticize Blizzard so aggressively for not doing both when nobody else does.
Implementing Two-Factor Authentication Is Easier Than It Seems
User and password verification with two-factor authentication isn’t as easy to use as plain old user and password, but with smartphones it comes very, very close. At the same time, the security benefits from having another secret stored on a different terminal are massive. Users’ accounts aren’t necessarily compromised if their passwords are.
In my mind, two-factor authentication is one of the least tedious things you can add that adds the most security to user accounts.
“But it’s a pain to add to your application, right?”
No! Just take a look at main() in this example that uses only the Python standard library:
#!/usr/bin/env python
import base64
import hashlib
import hmac
import os
import time
import struct
appName = "MyApp"
def newSecret():
return base64.b32encode(os.urandom(10))
def getQRLink(name, secret):
return "https://www.google.com/chart?chs=200x200&chld=M|0&cht=qr&chl=otpauth://totp/{0}%20-%20{1}%3Fsecret%3D{2}".format(name, appName, secret)
def auth(secret, nstr):
# raise if nstr contains anything but numbers
int(nstr)
tm = int(time.time() / 30)
secret = base64.b32decode(secret)
# try 30 seconds behind and ahead as well
for ix in [-1, 0, 1]:
# convert timestamp to raw bytes
b = struct.pack(">q", tm + ix)
# generate HMAC-SHA1 from timestamp based on secret key
hm = hmac.HMAC(secret, b, hashlib.sha1).digest()
# extract 4 bytes from digest based on LSB
offset = ord(hm[-1]) & 0x0F
truncatedHash = hm[offset:offset+4]
# get the code from it
code = struct.unpack(">L", truncatedHash)[0]
code &= 0x7FFFFFFF;
code %= 1000000;
if ("%06d" % code) == nstr:
return True
return False
def main():
# Setup
name = raw_input("Hi! What's your name? ")
pw = raw_input("What's your password? ")
secret = newSecret() # store this with the other account information
link = getQRLink(name, secret)
print("Please scan this QR code with the Google Authenticator app:\n{0}\n".format(link))
print("For installation instructions, see http://support.google.com/accounts/bin/answer.py?hl=en&answer=1066447")
print("\n---\n")
# Authentication
opw = raw_input("Hi {0}! What's your password? ".format(name))
if opw != pw:
print("Sorry, that's not the right password.")
else:
code = raw_input("Please enter your authenticator code: ")
if auth(secret, code):
print("Successfully authenticated! Score!")
else:
print("Sorry, that's a fail.")
if __name__ == "__main__":
main()Not using Python, and don’t want to port this code? There are many TOTP libraries available that are just as easy to use!
If you don’t implement two-factor authentication in your applications, please consider supporting a federated authentication mechanism like OAuth or OpenID so users can leverage providers that do.
Code based on example by brool.
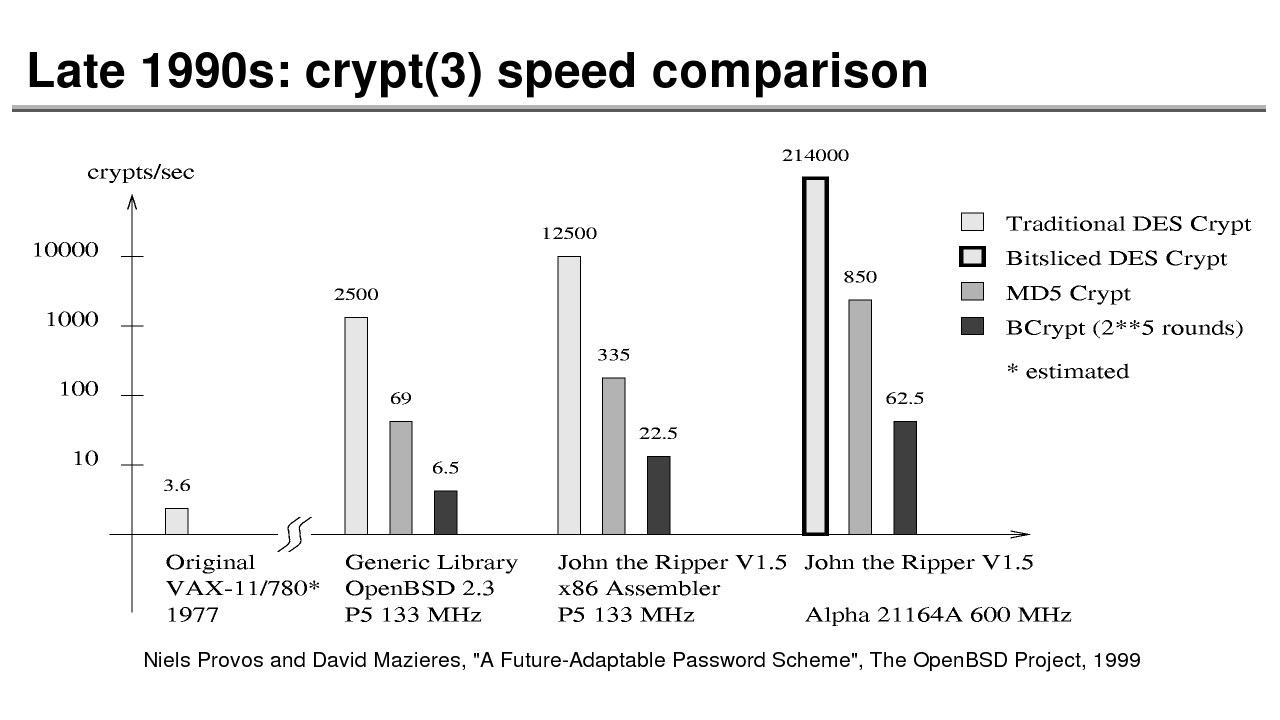
The History of Password Security
What better way to follow up on my post about storing passwords securely than to take a look at how password hashing has evolved over the years?
I think you’re likely to be surprised by what “new” things were being done all the way back in the 70s!
These slides are courtesy of Openwall’s Alexander Peslyak, perhaps better known as Solar Designer. The original high-resolution versions, and a PDF with all the slides, can be found here.